KeplerFS 🚀
A Leaderless, Distributed Peer-to-Peer File System
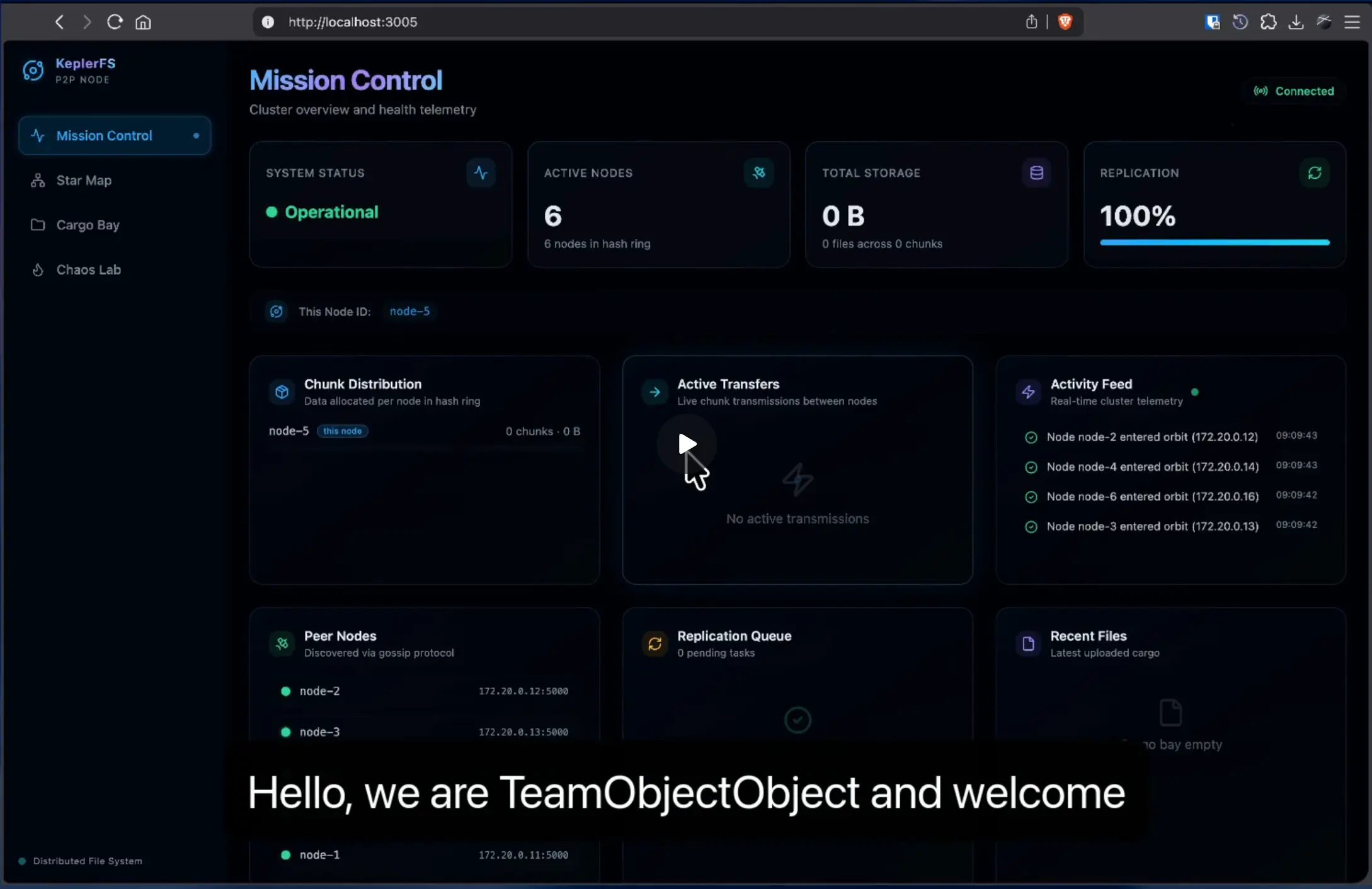
KeplerFS is a masterless, distributed file system where every node runs the same binary — acting simultaneously as an HTTP gateway, gossip peer, and chunk store. No single point of failure, no master node, pure peer-to-peer architecture.
🎯 Project Overview
KeplerFS revolutionizes distributed storage by providing:
- Masterless Architecture: All nodes are peers; any node can accept reads and writes
- Content-Addressed Storage: Every chunk identified by SHA-256 digest for deduplication and integrity verification
- Consistent Hash Ring: Deterministic, low-disruption chunk placement across the cluster
- SWIM-Inspired Gossip: Automatic peer discovery and failure detection over UDP
- Crash-Safe Replication: SQLite-backed replication queue ensures at-least-once delivery after restarts
- Atomic Writes:
tmp → fsync → renamesequence prevents torn chunks on disk - Configurable Durability: Choose between
quorum(strong) andfast(async) write acknowledgement per request
🏗️ System Architecture
Three Concurrent Interfaces on Each Node
Browser UI ──HTTP──► [Node A] ◄──gossip/UDP──► [Node B] ◄──► [Node C]
│ │
local chunks local chunks
Each node exposes simultaneously:
- HTTP Gateway (TCP/HTTP): Accepts client uploads and downloads
- Gossip Peer (UDP): Peer discovery and failure detection
- Chunk Transfer (TCP): Direct chunk streaming between nodes
📝 How File Writes Work
1. Chunking & Hashing
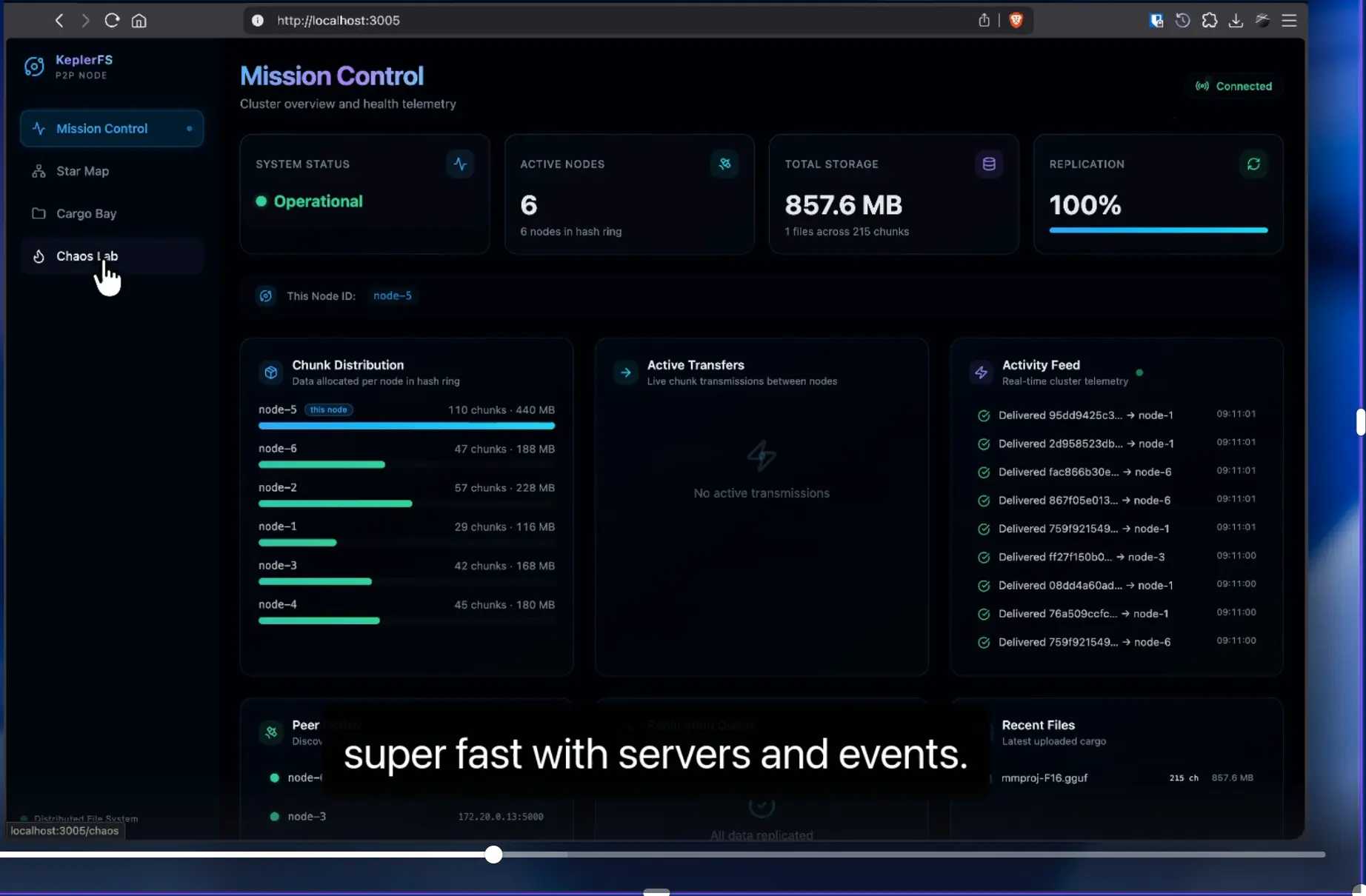
The receiving node splits files into fixed-size chunks (default 4 MB). Each chunk is content-addressed with SHA-256, providing deduplication and integrity verification for free.
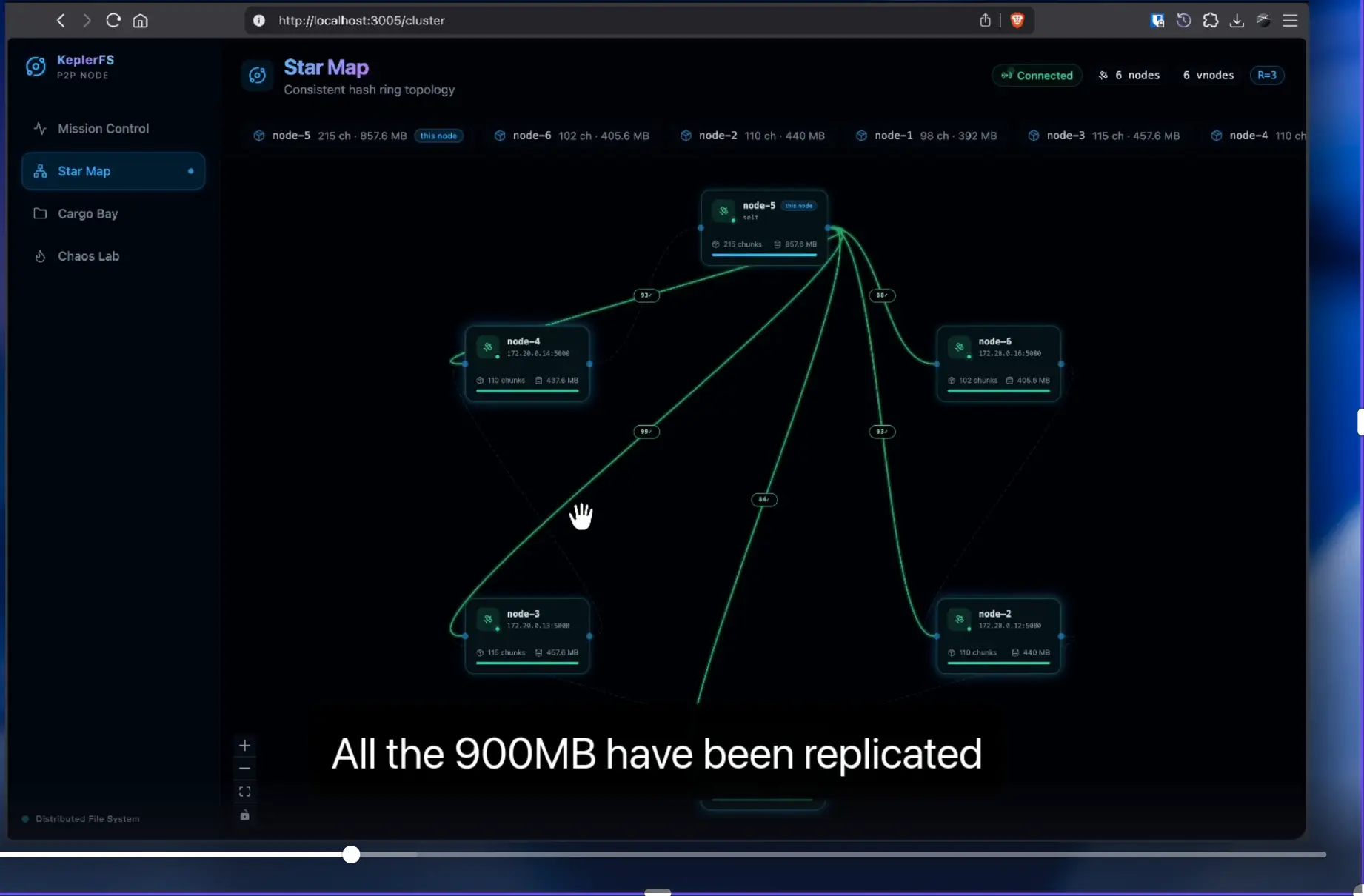
2. Consistent Hash Ring
Every node holds a position on a consistent hash ring derived from its node ID. Each chunk maps to the N closest nodes clockwise (N = replication factor, default 3). The receiving node immediately knows which chunks are local and which must be forwarded.
3. Replication Pipeline
Local chunks are written atomically (tmp → fsync → rename). Remote chunks are enqueued in SQLite and streamed to target nodes over TCP. The client receives 200 only after local writes + (N−1) remote ACKs (configurable via ?durability=quorum|fast).
4. Gossip Protocol
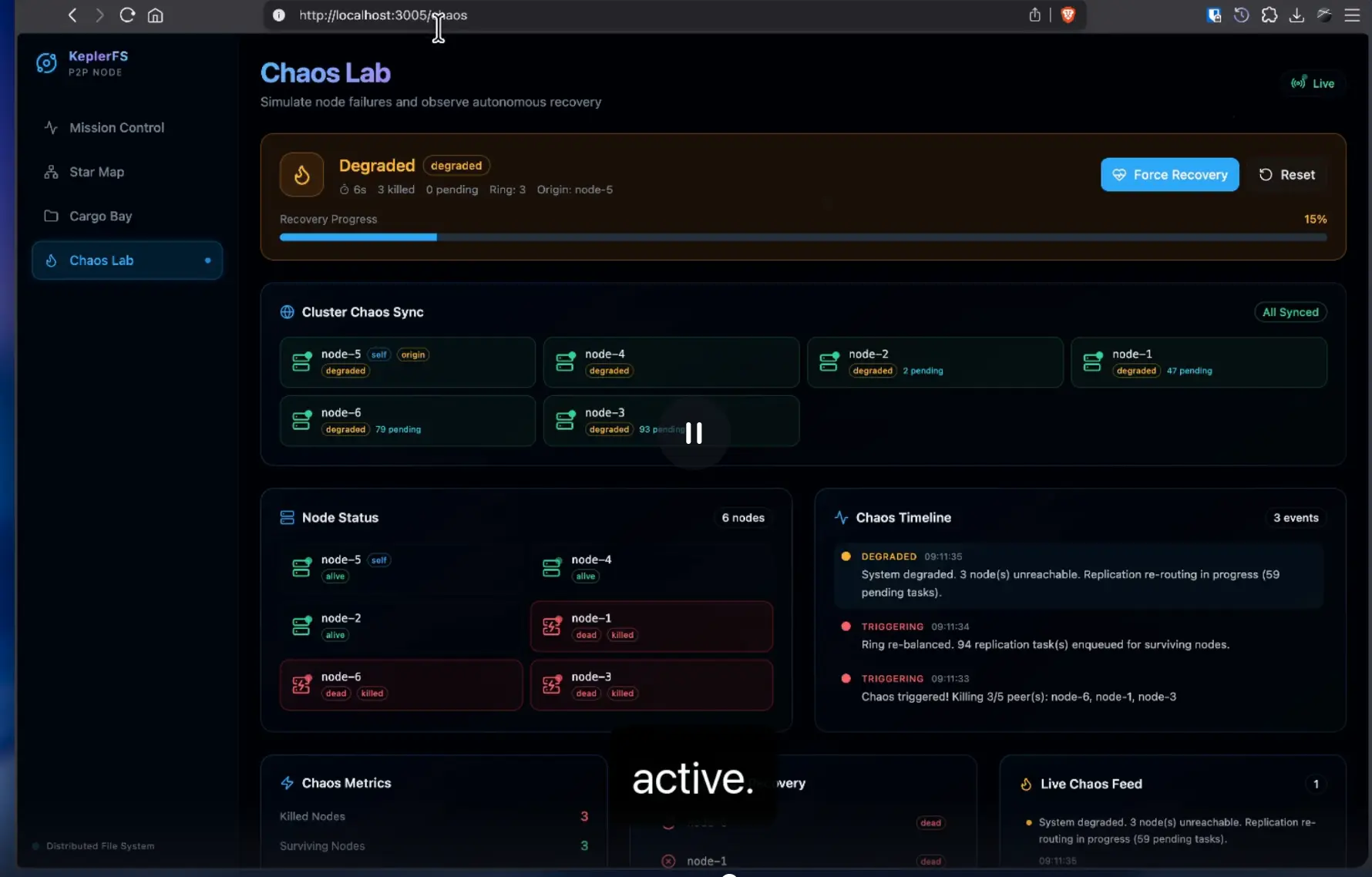
Nodes discover each other and maintain the ring via SWIM-inspired UDP gossip. Missed heartbeats promote peers to suspect, then dead. Dead peers trigger automatic re-replication of their chunks across surviving nodes.
5. Rebalancing on Join
When a new node joins, its clockwise neighbour detects it now owns fewer chunks and streams the handoff set in the background. The ring is updated immediately; handoff happens asynchronously with a grace-period deletion timer.
🗂️ Monorepo Structure
KeplerFS/
├── apps/
│ └── frontend/ # SvelteKit 5 web UI
└── packages/
└── node/ # Bun P2P node binary
| Component | Purpose |
|---|---|
packages/node | HTTP gateway, gossip peer, chunk store |
apps/frontend | Upload, download, and cluster visualization UI |
🚀 Getting Started
Prerequisites
- Bun ≥ 1.2 — Runtime and compiler for packages/node
- pnpm ≥ 10 — Monorepo package manager
Install Dependencies
pnpm install
Run a Local 3-Node Cluster
Open three terminals and run each command in its own session:
# Terminal 1 — seed node
cd packages/node
NODE_ID=node-a HTTP_PORT=3001 GOSSIP_PORT=4001 TRANSFER_PORT=5001 \
pnpm run dev
# Terminal 2
NODE_ID=node-b HTTP_PORT=3002 GOSSIP_PORT=4002 TRANSFER_PORT=5002 \
SEEDS=127.0.0.1:4001 pnpm run dev
# Terminal 3
NODE_ID=node-c HTTP_PORT=3003 GOSSIP_PORT=4003 TRANSFER_PORT=5003 \
SEEDS=127.0.0.1:4001 pnpm run dev
The UI is available at http://localhost:5173.
Compile to a Single Binary
cd packages/node
pnpm run build
# Output: dist/kepler-node
Run Tests
cd packages/node
bun test
⚙️ Configuration
All configuration is supplied via environment variables:
| Variable | Default | Description |
|---|---|---|
NODE_ID | required | Unique identifier for this node |
HTTP_PORT | 3000 | Port for the HTTP gateway |
GOSSIP_PORT | 4000 | UDP port for gossip messages |
TRANSFER_PORT | 5000 | TCP port for chunk transfer |
SEEDS | — | Comma-separated host:gossip_port of known peers |
REPLICATION_FACTOR | 3 | Number of nodes each chunk is replicated to |
CHUNK_SIZE_MB | 4 | Maximum chunk size in megabytes |
REBALANCE_BANDWIDTH_MBPS | 50 | Rebalance bandwidth cap per node (MB/s) |
📊 Data Model
Each node maintains a local SQLite database:
-- Chunks stored on this node
chunks(
id TEXT PRIMARY KEY,
file_id TEXT,
index INT,
size INT,
path TEXT,
created_at INT
)
-- File manifests propagated via gossip
files(
id TEXT PRIMARY KEY,
name TEXT,
size INT,
chunk_ids JSON,
owner_node TEXT,
created_at INT
)
-- Known peers and their health status
peers(
id TEXT PRIMARY KEY,
addr TEXT,
gossip_port INT,
transfer_port INT,
last_seen INT,
status TEXT -- 'alive' | 'suspect' | 'dead'
)
-- Crash-safe outbound replication queue
replication_queue(
chunk_id TEXT,
target_node_id TEXT,
attempts INT,
last_attempt INT,
PRIMARY KEY (chunk_id, target_node_id)
)
🛡️ Fault Tolerance
| Failure Mode | Handling Strategy |
|---|---|
| Split Brain | AP design — accept divergence, reconcile on merge; fencing tokens on writes |
| Thundering Herd on Rejoin | Per-node rebalance bandwidth cap (default 50 MB/s) |
| Chunk Transfer Atomicity | Write to *.tmp, fsync, then rename(2) |
| Crash Mid-Replication | replication_queue table; pipeline resumes on restart |
| Node Failure | Gossip detects dead peers and triggers automatic re-replication |
📸 Project Showcase
[Images will go here]
🤝 Team & Contributors
Built by a talented team of distributed systems enthusiasts:
- WhyAsh5114 (Yash Kolekar)
- jaykerkar0405 (Jay Kerkar)
- sundaram123krishnan (Sundaram Krishnan)
- kryyo1441 (Aayush Nair)
📜 License
Released under the MIT License. © 2026 KeplerFS Contributors.
🔗 Links
- Repository: github.com/Crew-object-Object/KeplerFS
- Built At: HackX 4.0 (Feb 28 - Mar 1, 2026)